软件和硬件
操作系统
操作系统就是管理计算机的硬件软件和资源,并且为软件运行提供通用服务的系统软件。
- 硬件管理,包括分配CPU时间、内存;从网络、存储设备等IO设备读写数据。
- 软件管理,就是各种软件的运行,线程、进程调度之类的工作。
- 为软件提供运行环境,这个运行环境通常一部分由操作系统内核(Kernel)提供,另一部分由运行库(Runtime Library)提供。

安迪-比尔定律:”what Andy giveth, Bill taketh away.”
随着硬件的性能提升,以及软件种类的丰富,有两种情况变得很常见:
- 硬件性能过剩——很多计算机的硬件配置,即使不能完全满足峰值性能的要求,也往往会有大量时间处于硬件资源闲置的状态。例如一般家用电脑,已经是四核、六核的配置了,除了3A游戏、视频制作、3D渲染、高性能计算等特殊应用外,通常有90%以上时间CPU是闲置的。
- 软件冲突——因为业务需要,两个或者多个软件之间冲突,或者需要同一个软件的不同版本。例如早几年做web前端的,要测试网页在不同版本的IE上是否能正常显示,然而Windows只能装一个版本的IE。
在硬件性能过剩的时候,硬件虚拟化的普及就很自然而然的提出来了。
云计算中的虚拟化和容器化
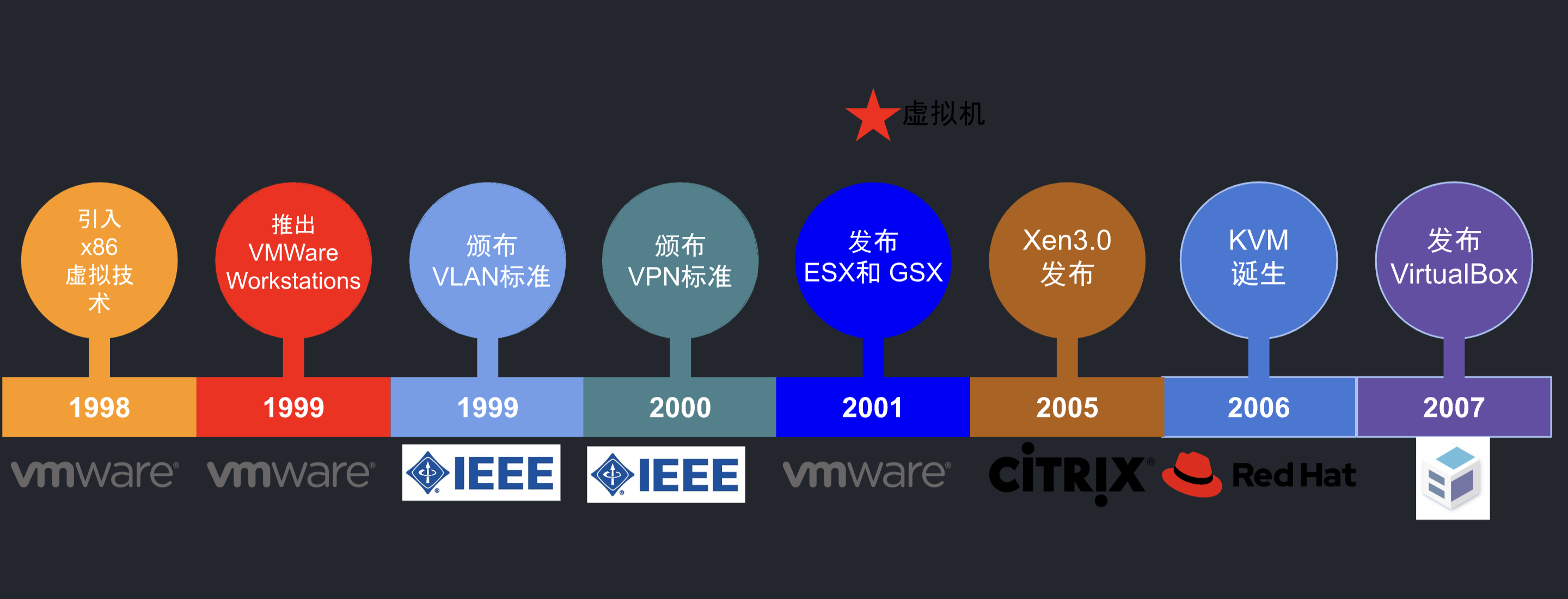
2000 年前后,虚拟化技术逐渐发展成熟,虚拟化技术的成熟,使得云计算市场开始真正出现。
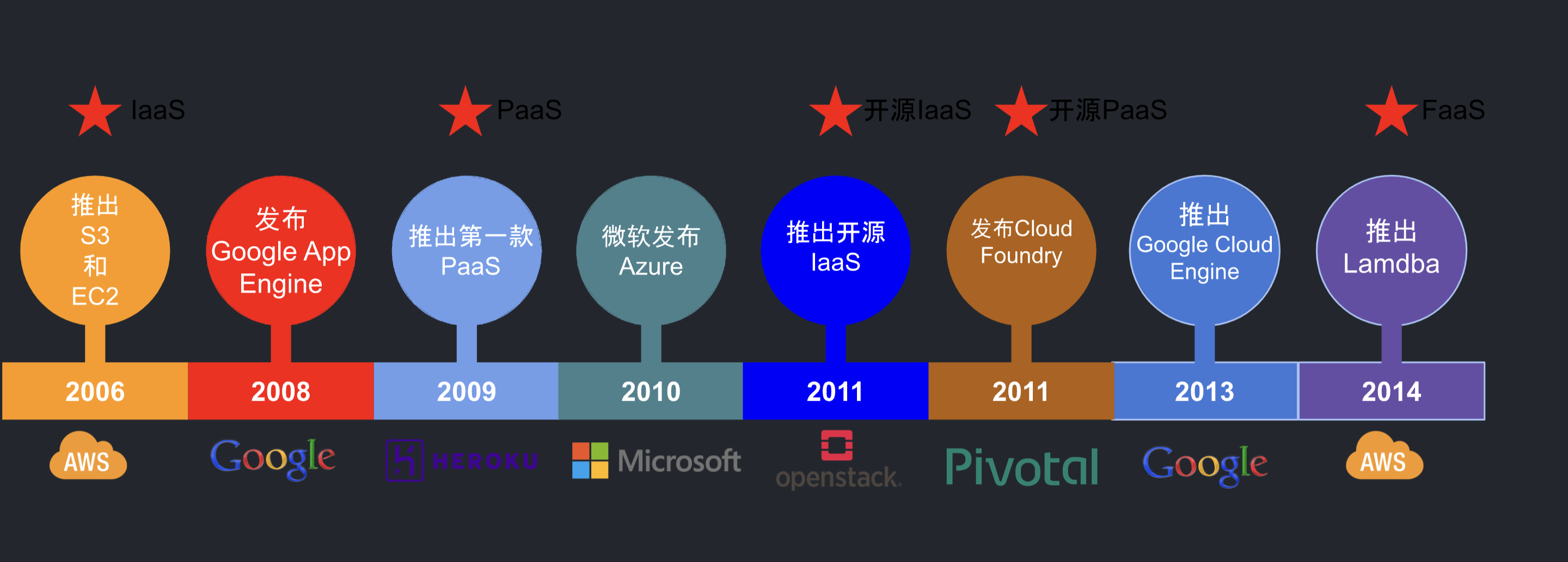
- IaaS(Infrastructure as a service,基础设施即服务)的出现:通过按时计费的方式租借服务器(卖资源),将资本支出转变为运营支出,这使得云计算得以大规模兴起和普及。
- PaaS(Platform as a service,平台即服务)的出现:使开发者不必费心考虑操作系统和开发工具更新或者硬件维护,云服务提供商由 IaaS 阶段的卖资源进阶为卖服务。
- 开源 IaaS 的出现:云计算开始进入开源时代。
- 开源 PaaS 的出现:云计算开始推动容器技术兴起
- FaaS(Function as a Service,功能即服务)的出现:通过 FaaS,物理硬件、虚拟机操作系统和 Web 服务器软件管理等等都由云服务提供商自动处理。无服务器(Serverless)的概念已经初现,开发者将无需再关注任何服务、资源等基础设施。
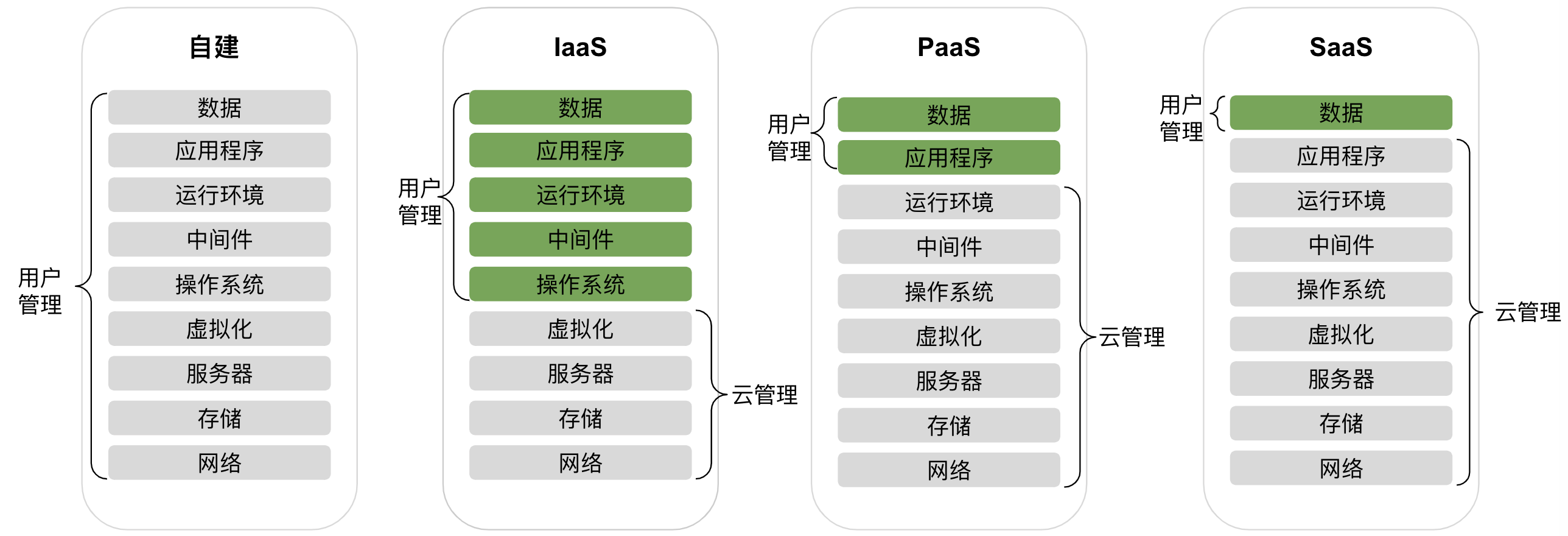
2013 年发生了一件影响深广的技术变革:Docker 降世。
从虚拟机到容器,整个云计算市场发生了一次重大变革,甚至是洗牌,基于容器技术的容器编排市场,则经历了 Mesos、Swarm、kubernetes 三家的一场史诗大战,最终以 kubernetes 全面胜利而告终。
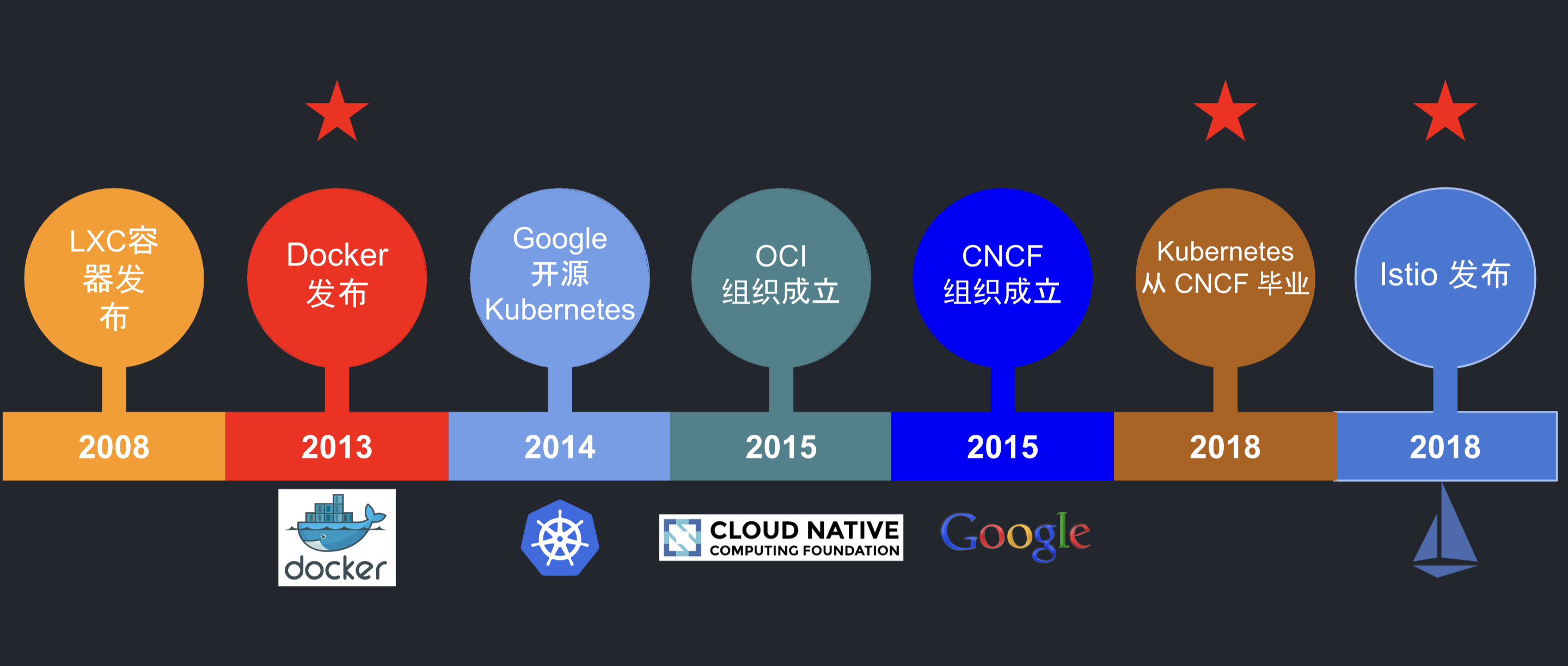
- 2013 年,Docker 发布,容器逐步替代 VM,云计算进入容器时代。
- 2017 年底,Kubernetes 赢得容器编排的胜利,云计算进入 Kubernetes 时代。
- 2018 年,Istio 正式发布,服务网格(ServiceMesh)从理念走向成熟。
对云计算演进总结分析,可以发现以下规律:
- 核心构建块的变化:从早期的物理服务器,通过虚拟化技术演进为虚拟机,再通过容器化技术演进为目前的 container。
- 隔离单元:无论是启动时间还是单元大小,物理机、虚拟机、容器一路走来,实现了从重量级到轻量级的转变。
- 供应商:从闭源到开源,从单一供应商到跨越多个供应商。
虚拟化
所谓硬件虚拟化,就是某个特殊的软件,仿真出一台或者多台计算机的各种硬件,用户可以在这一台虚拟机上安装、运行操作系统(一般叫来宾操作系统,Guest OS)和各种应用,并且把Guest OS和上面应用软件对硬件资源的访问转发到底层的硬件上来实现。对于Guest OS和上面的应用程序来说,这台虚拟机和普通的物理计算机是完全一样没有任何区别的——除了性能可能差一点。著名的VMware就是这么一个软件,这类软件英语有一个专用的单词是Hypervisor(维基的Hypervisor词条说另一种叫法是虚拟机监视器)
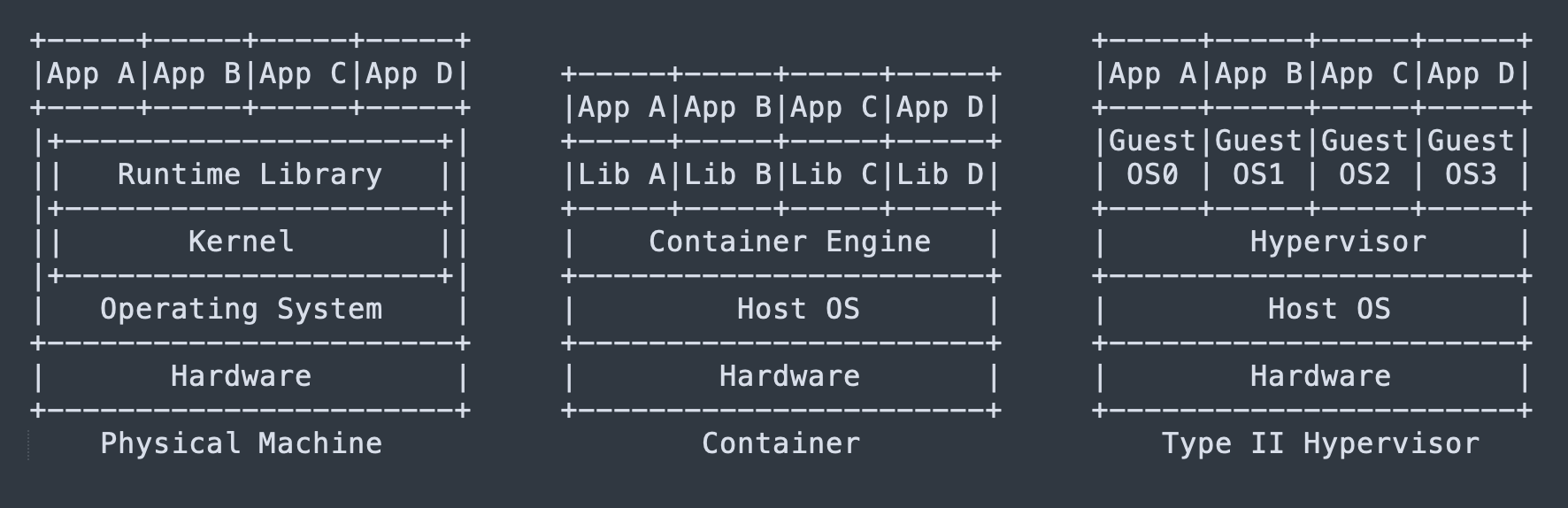
容器化
chroot
能否在现有的操作系统环境下,隔离出一个用来重构和测试软件的独立环境?于是,一个叫做 chroot(Change Root)的系统调用功能就此诞生。
chroot 被认为是最早的容器化技术之一,chroot 可以重定向进程及其子进程的 root 目录到文件系统上的新位置,也就是说使用它可以分离每个进程的文件访问权限,使得该进程无法接触到外面的文件,因此这个被隔离出来的新环境也得到了一个非常形象的命名,叫做 Chroot Jail(监狱)。
这便是容器最重要的特性–进程隔离。
虽然chroot是一种简单而有效的容器化技术,但它也存在一些限制。例如,chroot只能限制进程对文件系统的访问,而不能限制进程对其他系统资源的访问,如网络、进程、用户等
容器的核心技术
主要有三点:使用 Namespace 用来进行资源隔离、使用 Cgroups 进行资源限制、基于 Unionfs 设计了镜像分层机制
- Linux 通过对内核资源进行封装抽象,提供了八类系统资源的隔离(Namespace):
| 类型 | 用途 |
|---|---|
| Cgroup | Cgroup root directory cgroup 根目录 |
| IPC | System V IPC, POSIX message queues 信号量,消息队列 |
| Network | Network devices, stacks, ports, etc.网络设备,协议栈,端口等等 |
| Mount | Mount points 挂载点 |
| PID | Process IDs 进程号 |
| User | 用户和组 ID |
| UTS | 系统主机名和 NIS(Network Information Service) 主机名(有时称为域名) |
| Time | 时钟 |
Cgroups
- cgroup的api以一个伪文件系统的实现方式,用户的程序可以通过文件系统实现cgroup的组件管理
- cgroup的组件管理操作单元可以细粒度到线程级别,另外用户可以创建和销毁cgroup,从而实现资源载分配和再利用
- 所有资源管理的功能都以子系统的方式实现,接口统一子任务创建之初与其父任务处于同一个cgroup的控制组
四大功能:
- 资源限制:可以对任务使用的资源总额进行限制
- 优先级分配:通过分配的cpu时间片数量以及磁盘IO带宽大小,实际上相当于控制了任务运行优先级
- 资源统计:可以统计系统的资源使用量,如cpu时长,内存用量等
- 任务控制:可以对任务执行挂起、恢复等操作
Unionfs
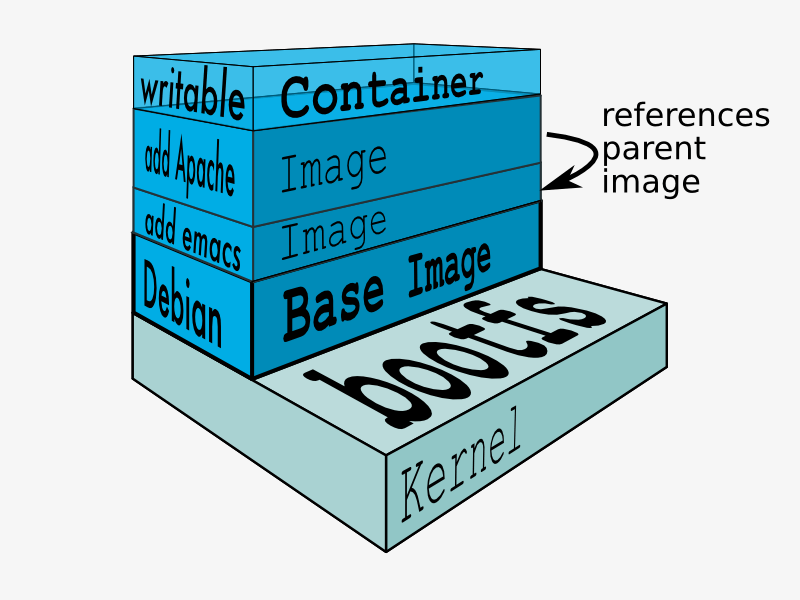
联合文件系统(Union File System, UnionFs)它可以不同物理位置的目录合并、挂载到同一个目录中,而实际上目录的物理位置是分开的。UnionFs 把文件系统的每一次修改作为一个个层进行叠加,同时可以将不同目录挂载到同一个虚拟文件系统下。如果一次同时加载多个文件系统,UnionFs 会把各层文件叠加起来,最终文件系统会包含所有底层文件和目录,从外部视角看,就是一个完成的文件系统。
容器镜像设计中,为了解决各类依赖以及依赖共享,正是利用 UnionFs 实现了镜像分层,再结合 bootfs、rootfs,一层层继承、叠加。启动容器时把相关的层挂载到一个目录,作为容器的根文件系统,这就是容器镜像的原理。
- bootfs(boot file system):包含操作系统 bootloader 和 kernel。用户不能修改 bootfs,在内核启动后,bootfs 会被卸载。
- rootfs(root file system):包含系统常见的目录结构,如/dev 、/lib、/proc、/bin、/etc/、/bin 等
Docker
why docker?
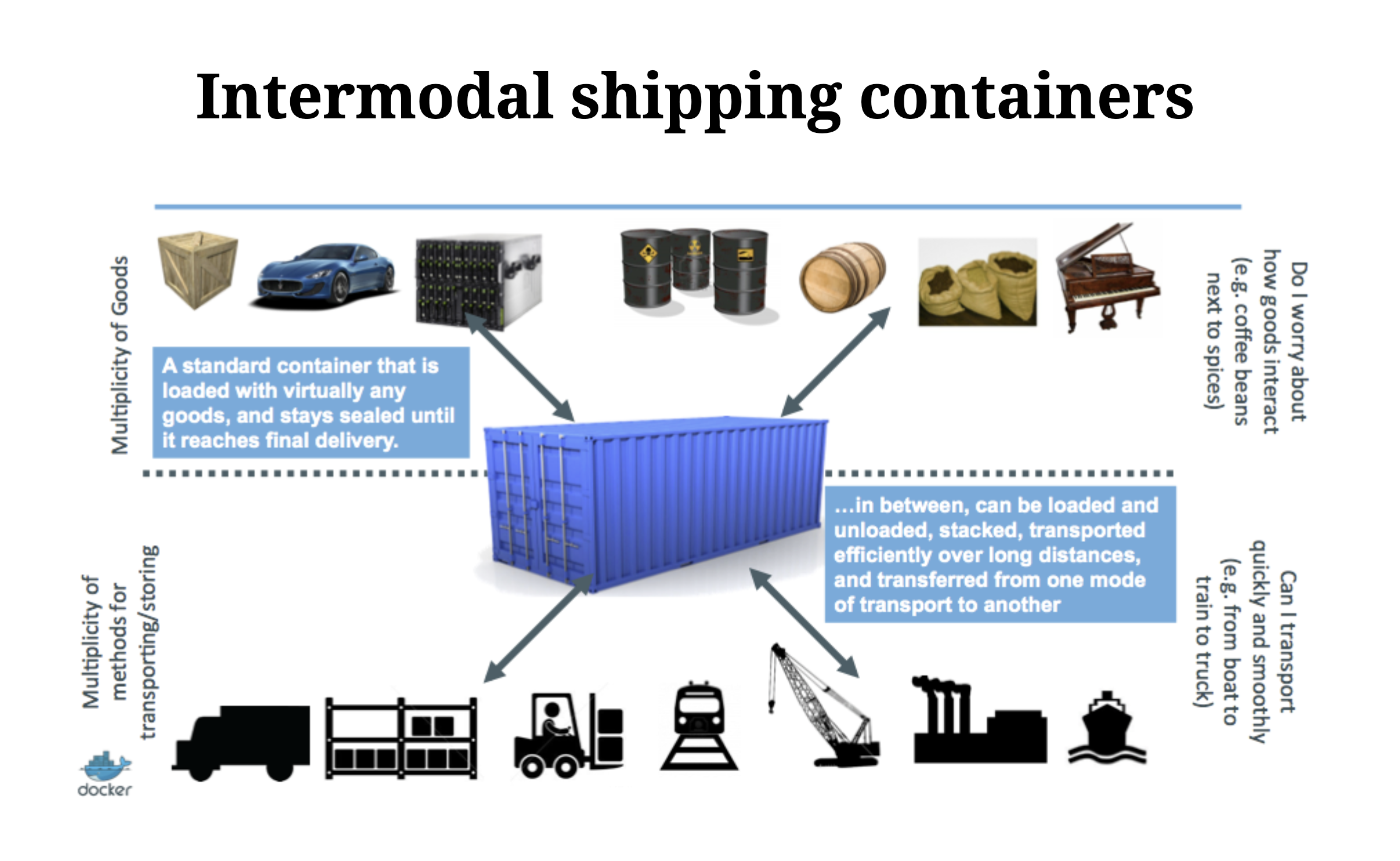
Build, Ship, And Run Any App, Anywhere
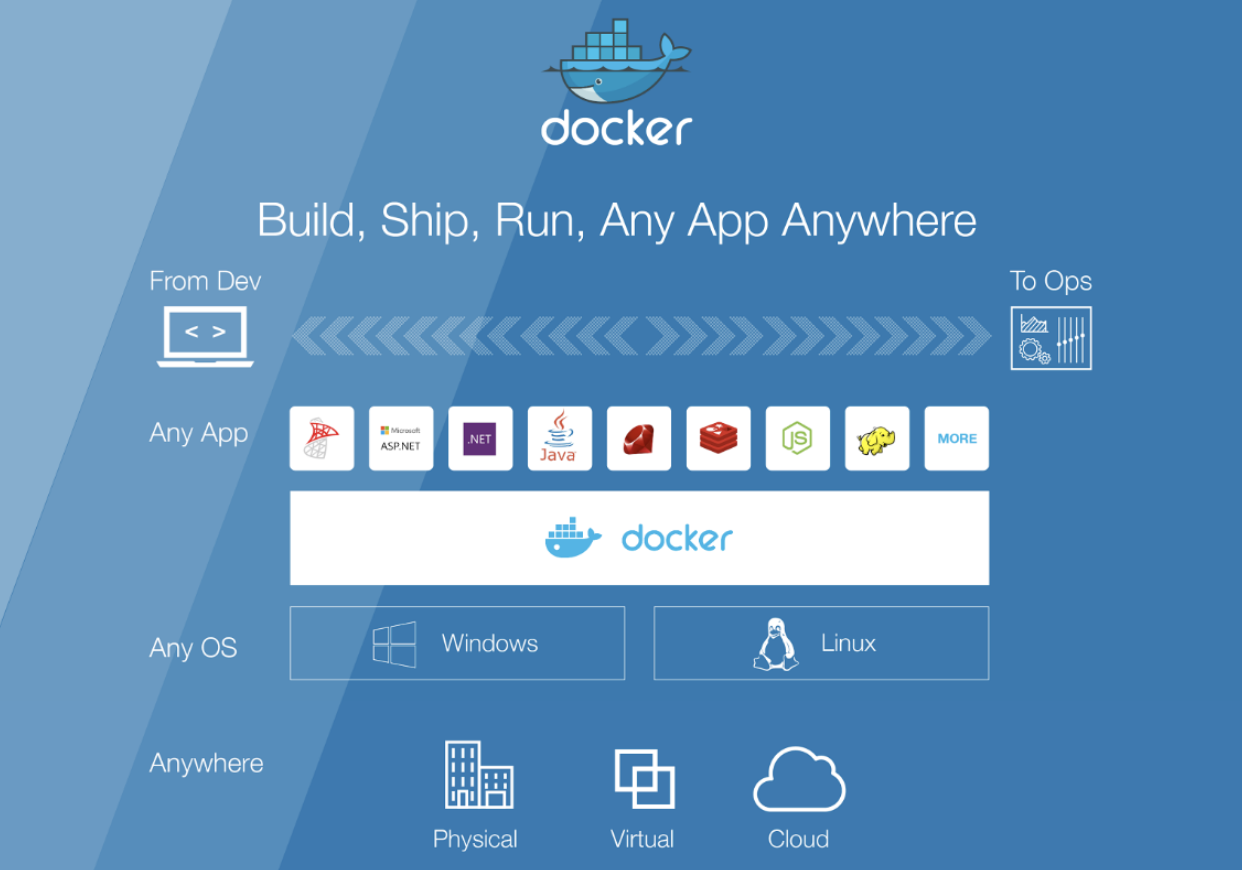
Docker 的核心创新”容器镜像(container image)”:
- 容器镜像打包了整个容器运行依赖的环境,以避免依赖运行容器的服务器的操作系统,从而实现”build once,run anywhere”。
- 容器镜像一但构建完成,就变成 read only,成为不可变基础设施的一份子。
- 操作系统发行版无关,核心解决的是容器进程对操作系统包含的库、工具、配置的依赖,但是容器镜像无法解决容器进程对内核特性的特殊依赖。
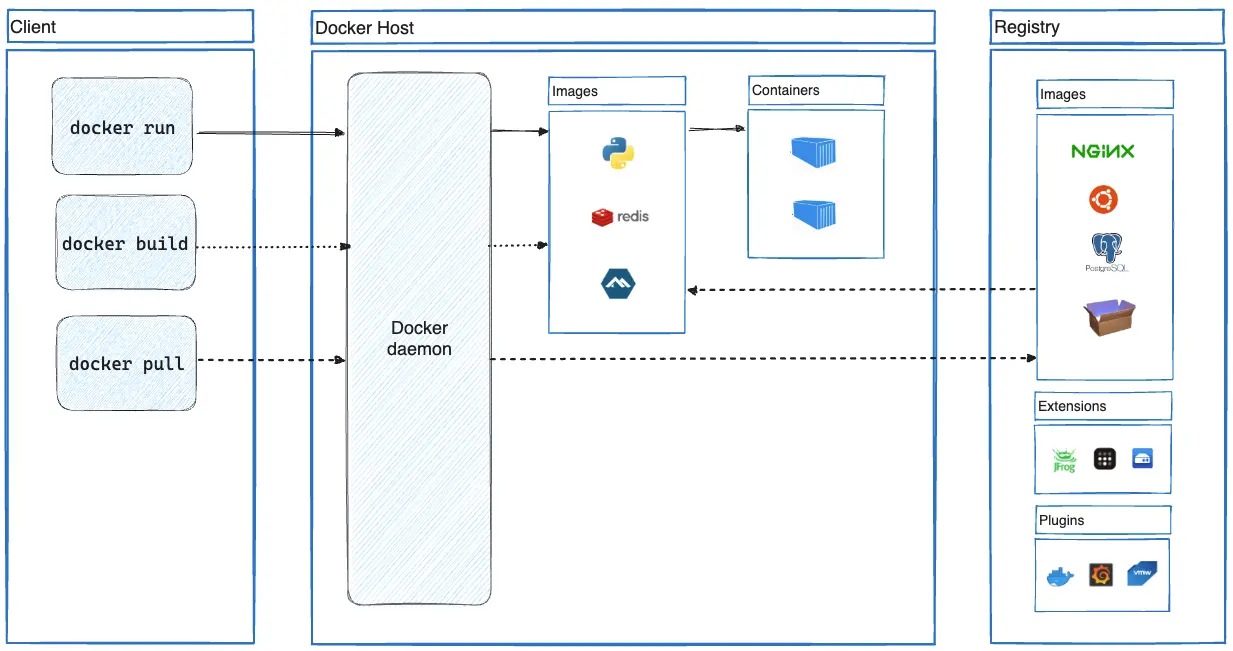
2015 年 6 月,Docker 带头成立 OCI(Open Container Initiative,开放容器标准),OCI 组织着力解决容器的构建、分发和运行问题,其宗旨是制定并维护容器镜像格式和容器运行时的正式规范(OCI Specifications)。
OCI 其核心产出是:
- OCI Runtime Spec(容器运行时规范):该规范定义了如何根据相应的配置构建容器运行时。
- OCI Image Spec(镜像格式规范):该规范定义了容器运行时使用的镜像的打包规范。
- OCI Distribution Spec(镜像分发规范)。
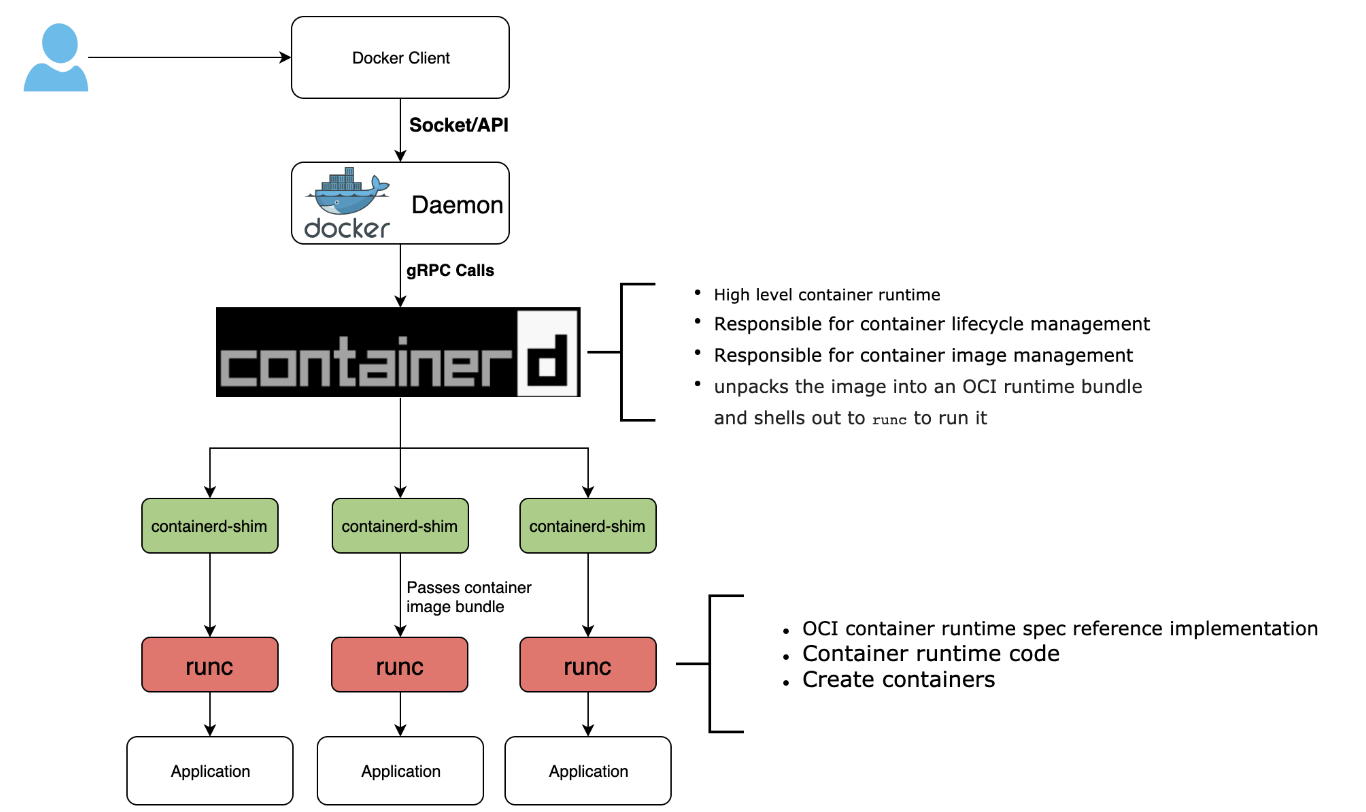
- 将 libcontainer 独立出来,封装重构成 runC 项目,并捐赠给 Linux 基金会管理,runC 是 OCI Runtime 的首个参考实现
- 与运行时交互的部分抽象为了 containerd 项目。这是一个负责管理容器执行、分发、监控、网络、构建、日志等功能的核心模块,其内部会为每个容器运行时创建一个 containerd-shim 适配进程,默认与 runC 搭配工作
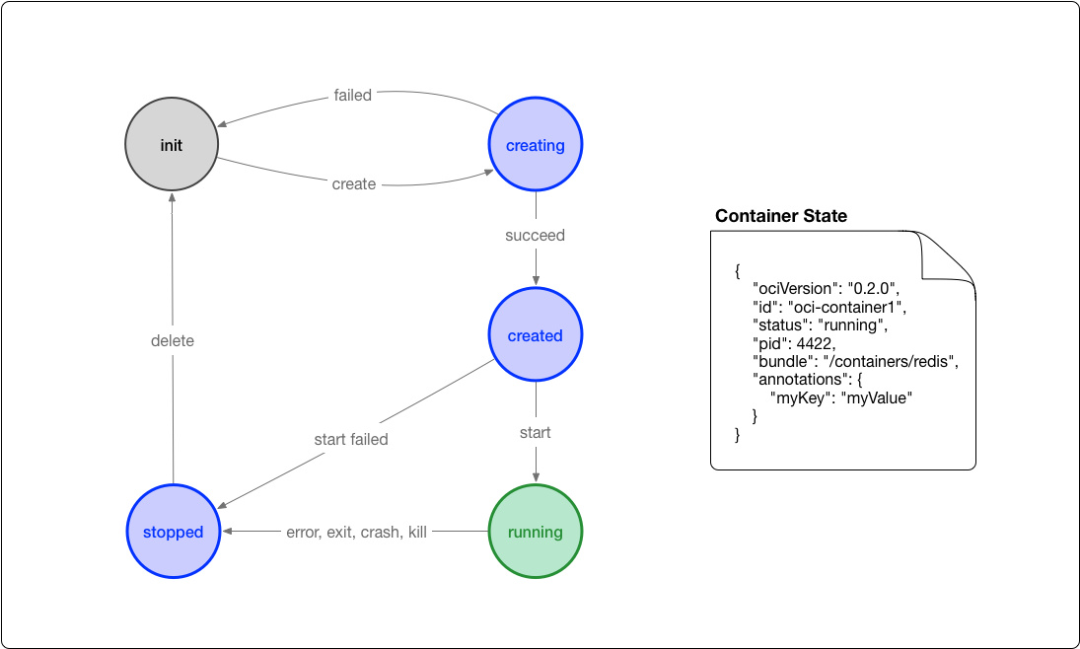
其他操作系统上的 docker
- windows: Hyper-V
- macOS:
从 Docker 到 K8s
如果说以 Docker 为代表的容器引擎,是把软件的发布流程从分发二进制安装包,转变为了直接分发虚拟化后的整个运行环境,让应用得以实现跨机器的绿色部署。那以 Kubernetes 为代表的容器编排框架,就是把大型软件系统运行所依赖的集群环境也进行了虚拟化,让集群得以实现跨数据中心的绿色部署,并能够根据实际情况自动扩缩。
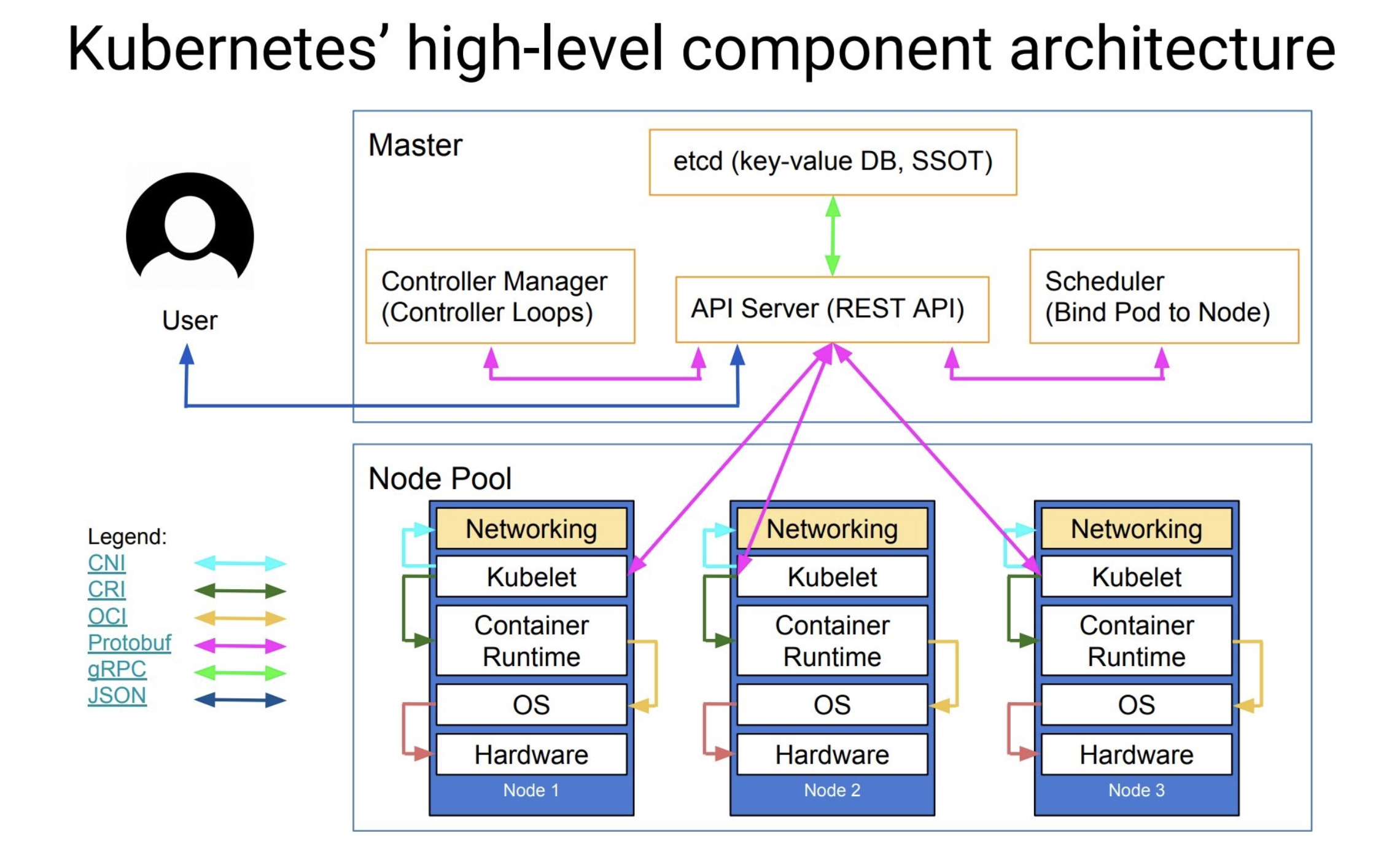
k8s 容器编排
参考资料
- 万字详解Docker架构原理、功能及使用
- 深入架构原理与实践 - 容器技术
- Container Training
- Docker,K8s,KVM,Hypervisor和微服务有什么区别联系吗?
- 一文搞懂 Docker、Containerd、RunC 间的联系和区别
- 浅析Docker、Containerd、RunC分别是什么
- docker、oci、runc以及kubernetes梳理
- runc 有代码
- Open Container Initiative
概念表
VM:VMware
VMware就这么一个软件。这个能够虚拟出一台或者多台电脑,并对这些虚拟机进行管理的软件,就是Hypervisor。知道VMware的大部分人都听说过两个版本:一个是VMware Workstation,一个是VMware ESXi。
KVM
而Linux从2.6.20开始,就从内核支持虚拟化,可以理解为内核就是Hypervisor的一部分,配合Qemu实现完整的Hypervisor功能。所以叫”基于内核的虚拟机(英语:Kernel-based Virtual Machine,缩写为KVM)”,不过因为内核部分跟近似于Type I但又不是完整的Hypervisor,Qemu部分则更接近于Type II,所以在维基的Hyperviso词条的Talk页面中,不少人为KVM属于Type I还是Type II而激烈争论。
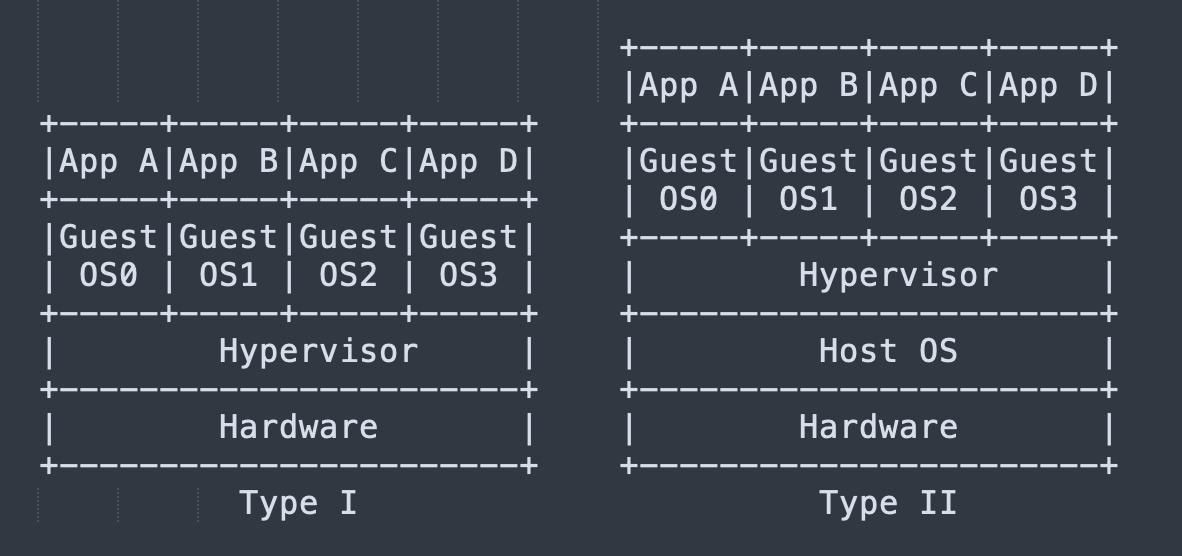
Hypervisor
Hypervisor根据其对硬件资源的访问方式,可以分为两大类,Type I是Hypervisor直接访问硬件资源,通常会有另一个操作系统运行于Hypervisor之上来对硬件资源,例如VMware EXSi,Windows的Hyper-V,Linux的Xen;Type II是Hypervisor和普通的应用一样,运行在某个操作系统(例如Windows或者Linux等,这里称之为宿主机操作系统,Host OS)之上,Hypervisor通过Host OS访问硬件资源,例如VMware Workstation,Virtual Box等。
ESXi属于Type I,Workstation属于Type II。Windows自带的Hyper-V,Linux上的Xen也属于Type I,Virtual Box之类的属于Type II。
Docker
Docker是目前最流行的容器引擎,它把容器技术从“只有运维专家才会用”变成了“开发者人人都能用”。Docker的核心创新是容器镜像(container image)——把应用和它依赖的整个运行环境打包成一个不可变的文件,真正做到“build once, run anywhere”。
OCI
OCI(Open Container Initiative,开放容器标准)是2015年由Docker带头成立、Linux基金会管理的组织,致力于制定容器的工业标准。它的核心产出是两个规范:容器运行时标准(runtime spec)定义了容器的状态和生命周期管理;容器镜像标准(image spec)定义了镜像的打包格式。这样做的好处是,不同厂商的容器工具可以互相兼容,不会被某一家绑定。
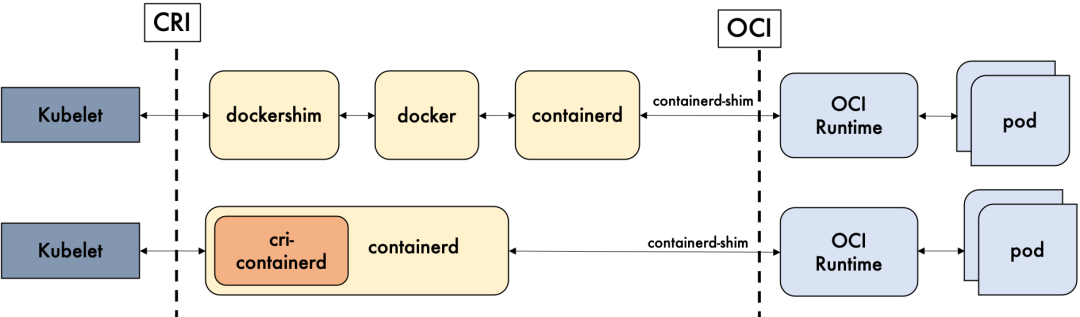
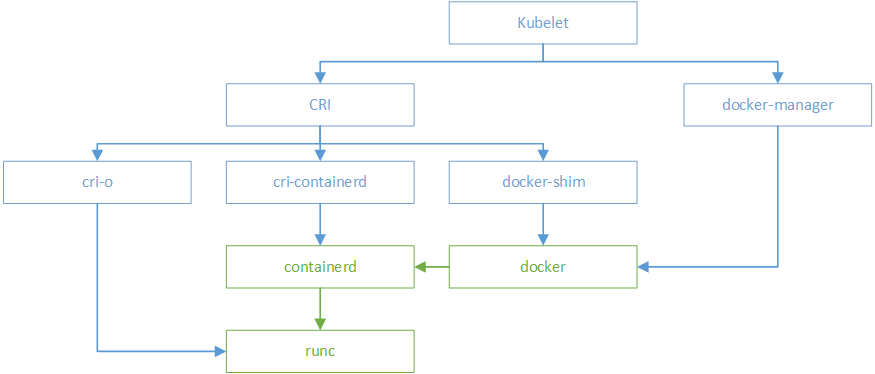
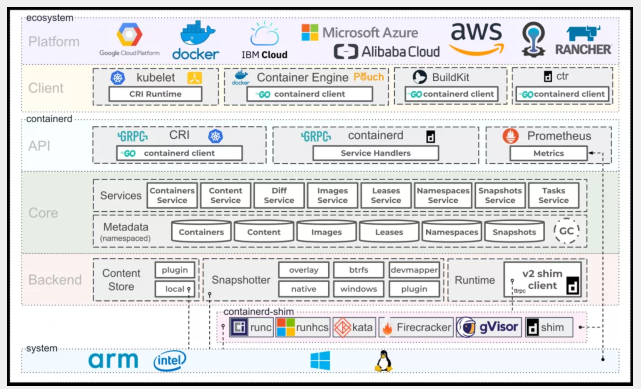
containerd
containerd是Docker从docker daemon中剥离出来的容器运行时核心模块,负责管理容器的完整生命周期,包括容器执行、分发、监控、网络、构建、日志等功能。它通过grpc与上层(Docker或Kubernetes)通信,接收“运行容器”的请求后,内部会为每个容器创建一个containerd-shim适配进程,最终调用runC来实际创建和运行容器。
containerd的意义在于,它把“管理容器”和“运行容器”这两件事拆开了:containerd做管理层的事,runC做底层运行的事,各司其职。
runC
runC是从Docker的libcontainer中独立、重构而来的,后来捐赠给Linux基金会,成为OCI Runtime Spec的首个参考实现。简单说,runC就是一个CLI工具,它负责真正和Linux内核打交道——配置cgroup、namespace,创建和启动容器进程。
当你执行docker run的时候,实际经历的步骤是:下载镜像→将镜像解开为bundle文件(文件系统拆分成多层)→从bundle运行容器。runC做的就是最后一步。它只关心“怎么把一个容器跑起来”,镜像拉取、网络、存储这些事情都不管。
既然runC只是OCI标准的一个实现,那自然还有其他符合OCI标准的容器运行时,比如Kata Containers、gVisor等,它们也可以通过containerd接入Docker或Kubernetes使用。
CRI
CRI(Container Runtime Interface,容器运行时接口)是Kubernetes定义的一套标准接口,让kubelet可以通过统一的协议来调用不同的容器运行时,而不用关心底层是Docker、containerd还是其他实现。
docker独立出来了containerd。kubernetes也顺应潮流,孵化了cri-containerd项目,用以将containerd接入到cri的标准中。
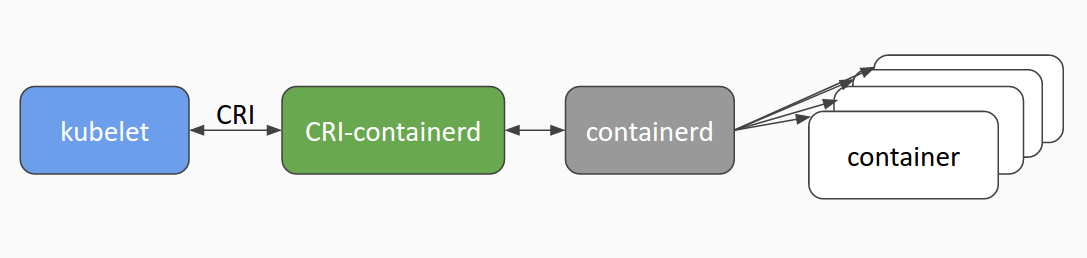
为了进一步与oci进行兼容,kubernetes还孵化了cri-o,成为了架设在cri和oci之间的一座桥梁。通过这种方式,可以方便更多符合oci标准的容器运行时,接入kubernetes进行集成使用。可以预见到,通过cri-o,kubernetes在使用的兼容性和广泛性上将会得到进一步加强。